Versión en español aquí
UPDATE: the script presented in this post is now part of a more complete and easy to use R package: JNplots !! Go check the post about it, and the paper !
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
When starting to write this post I wanted to give a small introduction to the analysis of covariance (ANCOVA), because this post is in part based on that analysis. However, it might be better for you to review it by yourself if you need to.
As for any other statistical method ANCOVA assumes that certain conditions are met by the data. Depending on the question that you want to answer with ANCOVA, some of these assumptions might or might not be necessary to be met by the data (look here for a review about this subject)
However, there is an assumption that must be met if one wants to determine differences between groups. This is the assumption of homogeneity of the regression slopes.
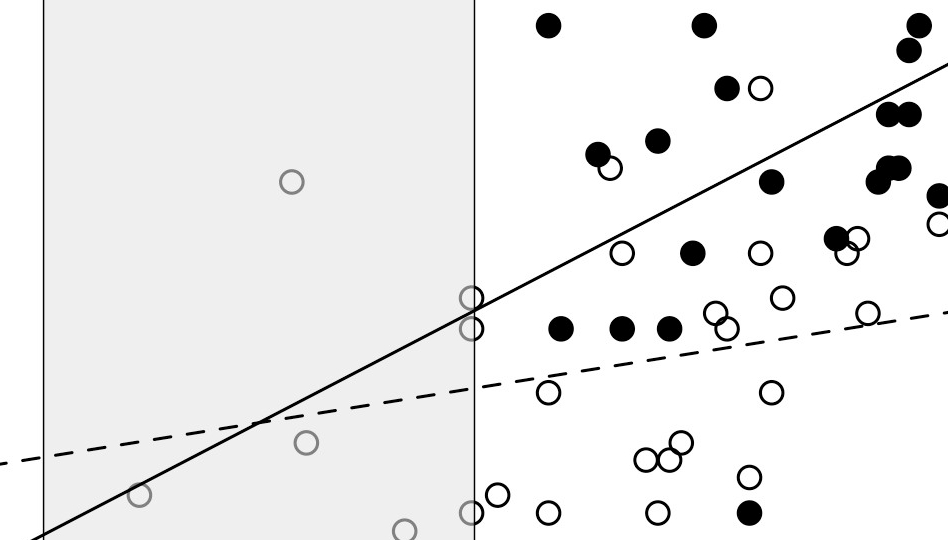
Let’s imagine that we want to compare the height of the head between males and females of a species of lizard (in lizards, taller heads are generally related to the consumption of larger prey and also to a better performance fighting against other individuals). Knowing that the head height in these animals covaries in respect to the head length we perform an ANCOVA. In the following figure we see the regression lines of males (black dots) and females (white dots) that represent the relationship between head height and length, and clearly we can notice that the assumption of homogeneity of the regression slopes is not met. It is enough to see how the regression lines are quite different in their “inclination”.
This will be confirmed if we perform the ANCOVA because the interaction between covariate (head length) and independent variable (sex) will be significant, indicating that the slopes are significantly different. Once the ANCOVA confirms this we can not compare between sexes using this method. What to do in this case?
I had this problem and, surprisingly, the solution was not that easy to find. I was a bit frustrated because, as you can see in the previous figure, is quite obvious that for a given head length males show higher heads than females, but I was not able to prove it statistically. My search became something similar to what you would expect from a detective novel, and from paper to paper I finally found a somewhat obscure method but that was supposed to solve my exact problem. This was the Johnson-Neyman technique.
Things of this method that surprised me:
– How hard was to find it.
– The precision with which it solved my problem.
– Its age! The original paper was published in 1936.
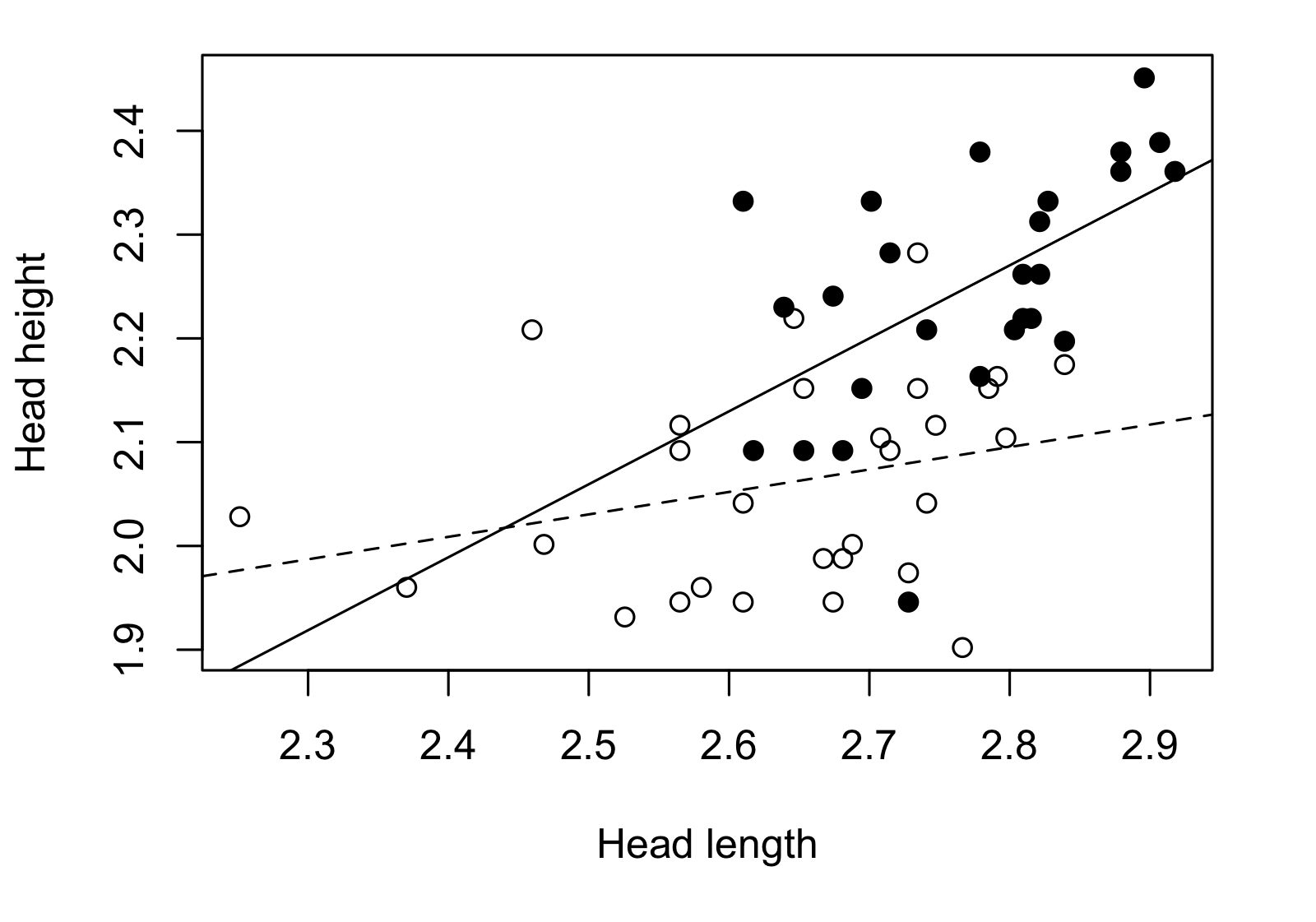
The JN technique is useful to solve cases like mine in which the regression slopes of the groups that I want to compare are different. This method generates a “non-significance zone”, that is basically an interval in the covariate within which there are no significant differences between groups. It is outside this interval where the groups are significantly different in respect to the dependent variable. The next figure might be good to explain what the method is about.
I didn’t read the original paper, but a more recent paper that more directly explained the method (White, 2003). After finding the method I needed, the next step was to find a software or R package/function that allowed me to apply it. The rarity of the method in the literature was also reflected in its implementation in statistical packages. I could only find some “drafts” of R scripts and even some SPSS codes that were not working for me.
So I decided to take a look at the mathematical basis of the method. Luckily, White’s paper showed the equations on which the JN technique was based. Even though they were somewhat tedious I decided to write an R script to be able to apply the method directly. I will leave the script at the end just in case it is useful for anyone.
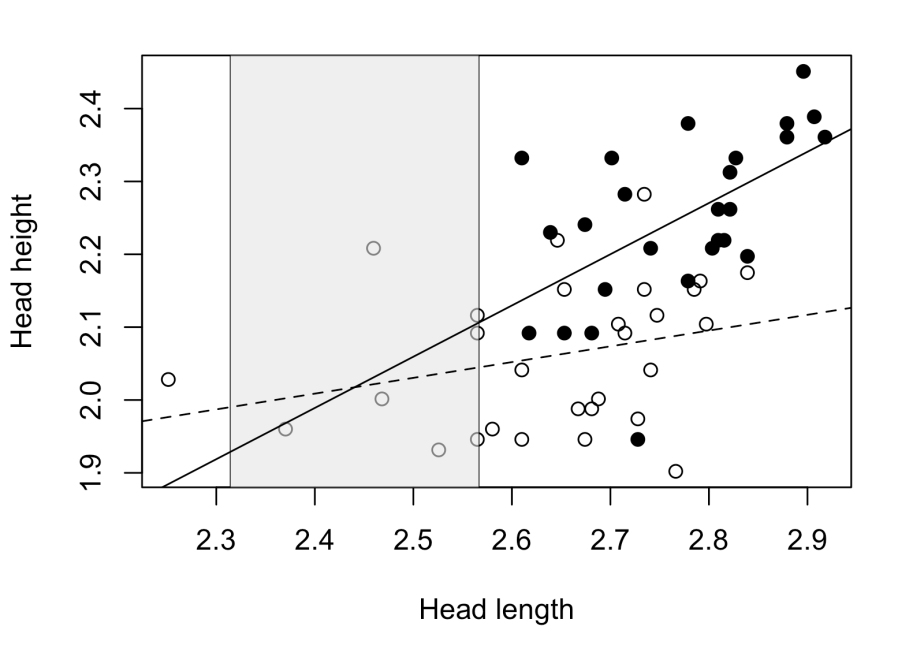
Applying the method through my script I obtained the following result for our example in lizards:
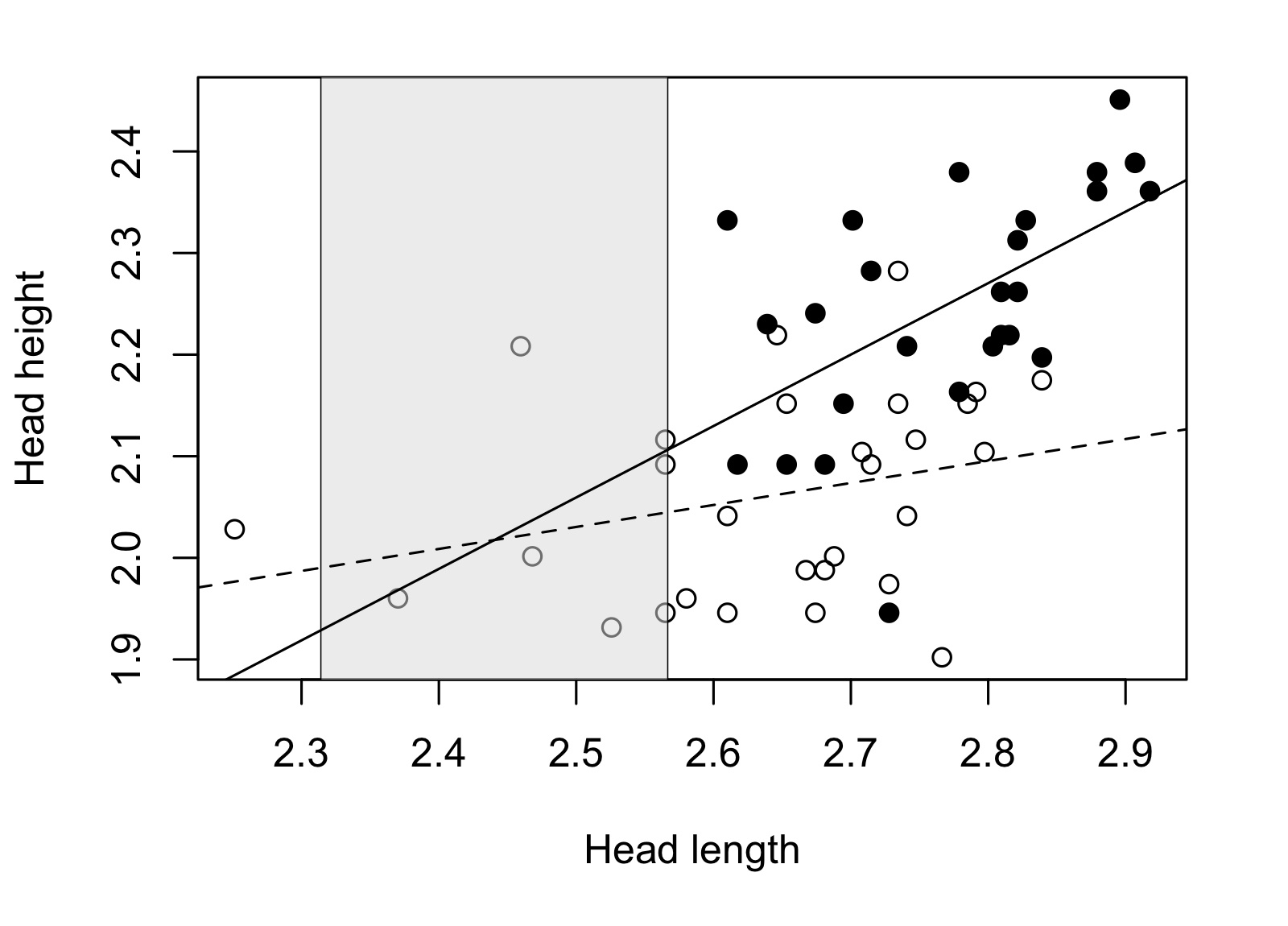
The non-significance zone is located in a head length interval for which there are almost no individuals to compare, actually there are no adult males in that zone. Most males and females are located out of the non-significance zone, where we can confidently affirm that the differences between males and females are significant. In consequence, we can conclude that adult males show higher heads than females for a given head length.
R script
Before starting, you need at least a dataset where rows are the cases and columns show the values of the dependent variable (in my example this was the head height), independent variable (e.g. sex) and covariate (e.g. head length).
The first step is then is to define your data table, which we will call “data”:
setwd("YourWorkingDirectory")
data <- read.table("YourData.txt",header=T, na.strings = c("x", "NA"))
I usually have my data in .txt format but the script can be modified to import excel (or you could convert your excel file to .txt)
The next step is to define your two* groups:
group1 <- data[ which(data$groups=="0"), ] group2 <- data[ which(data$groups=="1"), ]
In this case I’m assuming that the column “groups” codifies both groups as “0” and “1”. This can vary in your own data.
So we define our groups as group1 and group2
*This script works for the case in which you want to compare 2 groups. I think the JN technique can be extended to consider more groups at the same time, but I did not look for more about how to do that.
In the next lines:
n1 <- 55 n2 <- 33
is necessary to change the number of cases there are for each group. In this case n1 corresponds to the number of cases of group1 and n2 corresponds to group2.
Finally:
X1 <- group1$hl X2 <- group2$hl Y1 <- group1$hh Y2 <- group2$hh
you have to change the last part of each of these lines, both “hl” and “hh”. For me these letters meant head length or head height. This must be modified depending on how your dependent variable and the covariate are defined in your dataset.
After that you only need to run the rest of the code:
reg1 <- lm(log(Y1)~log(X1))
reg2 <- lm(log(Y2)~log(X2))
coef1 <- reg1$coefficients
coef2 <- reg2$coefficients
Fcvalue <- qf(.95, df1=1, df2=n1+n2-4)
xmean1 <- mean(log(X1))
xmean2 <- mean(log(X2))
xmeansq1 <- mean((log(X1))^2)
xmeansq2 <- mean((log(X2))^2)
sumx1 <- 0
sumx2 <- 0
sumy1 <- 0
sumy2 <- 0
sumxy1 <- 0
sumxy2 <- 0
xcoord_group1 <- log(X1) # X1
ycoord_group1 <- log(Y1) # Y1
xcoord_group2 <- log(X2) # X2
ycoord_group2 <- log(Y2) # Y2
zx1 <- ((sum(xcoord_group1))^2)/n1
zx2 <- ((sum(xcoord_group2))^2)/n2
zy1 <- ((sum(ycoord_group1))^2)/n1
zy2 <- ((sum(ycoord_group2))^2)/n2
zxy1 <- ((sum(xcoord_group1))*(sum(ycoord_group1)))/n1
zxy2 <- ((sum(xcoord_group2))*(sum(ycoord_group2)))/n2
######## sumx1 ########
c <- 0
while (c<n1) {
sumx1 <- sumx1 + (((xcoord_group1[c+1])^2) - zx1)
c <- c+1
}
sumx1
######## sumx2 ########
c <- 0
while (c<n2) {
sumx2 <- sumx2 + (((xcoord_group2[c+1])^2) - zx2)
c <- c+1
}
sumx2
######## sumy1 ########
c <- 0
while (c<n1) {
sumy1 <- sumy1 + (((ycoord_group1[c+1])^2) - zy1)
c <- c+1
}
sumy1
######## sumy2 ########
c <- 0
while (c<n2) {
sumy2 <- sumy2 + (((ycoord_group2[c+1])^2) - zy2)
c <- c+1
}
sumy2
######## sumxy1 ########
c <- 0
while (c<n1) {
sumxy1 <- sumxy1 + (((xcoord_group1[c+1])*(ycoord_group1[c+1]))-zxy1)
c <- c+1
}
sumxy1
######## sumxy2 ########
c <- 0
while (c<n2) {
sumxy2 <- sumxy2 + (((xcoord_group2[c+1])*(ycoord_group2[c+1]))-zxy2)
c <- c+1
}
sumxy2
########################
########################
########################
######## SSres ########
SSres <- (sumy1-(((sumxy1)^2)/sumx1))+(sumy2-(((sumxy2)^2)/sumx2))
SSres
########################
########################
########################
######## ABC ########
a1 <- coef1[1]
a2 <- coef2[1]
b1 <- coef1[2]
b2 <- coef2[2]
A <- (-Fcvalue/(n1+n2-4))*(SSres)*((1/sumx1)+(1/sumx2))+((b1-b2)^2)
B <- (Fcvalue/(n1+n2-4))*(SSres)*((xmean1/sumx1)+(xmean2/sumx2))+((a1-a2)*(b1-b2))
C <- (-Fcvalue/(n1+n2-4))*(SSres)*(((n1+n2)/(n1*n2))+(xmeansq1/sumx1)+(xmeansq2/sumx2))+((a1-a2)^2)
########################
xlower <- (-B-sqrt((B^2)-A*C))/A
xupper <- (-B+sqrt((B^2)-A*C))/A
xlower
xupper
xlower and xupper will indicate the inferior and superior limits of the non-significance zone respectively.
Plot
To generate this figure:
I used this code:
plot(log(data$hl),log(data$hh), ylab="Head height", xlab="Head length") polygon(c(xlower,xlower,xupper,xupper),c(0,3.2,3.2,0), col=rgb(224, 224, 224,maxColorValue=255,alpha=130), border=NA) abline(v=xlower,lty=1, lwd=0.5) abline(v=xupper,lty=1, lwd=0.5) dat <- data[ which(data$group=="1"), ] points(log(dat$hl),log(dat$hh), pch=16 ,col="black") newdata <- data[ which(data$group=="1" ), ] abline(lm(log(newdata$hh) ~ log(newdata$hl))) newdata <- data[ which(data$group=="0" ), ] abline(lm(log(newdata$hh) ~ log(newdata$hl)), lty=2)
References:
– Johnson, P. O., & Neyman, J. (1936). Tests of certain linear hypotheses and their application to some educational problems. Statistical research memoirs.
– White, C. R. (2003). Allometric analysis beyond heterogeneous regression slopes: use of the Johnson-Neyman technique in comparative biology. Physiological and Biochemical Zoology, 76(1), 135-140.
La técnica de Johnson-Neyman y un script de R para aplicarla
ACTUALIZACIÓN: el script presentado en este post es ahora parte de un paquete de R más completo y fácil de usar: JNplots !! Ve de qué se trata en este post, y lee el paper !
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
Al empezar a escribir este post quise dar una pequeña introducción al análisis de covarianza (ANCOVA), ya que el post se basa bastante en este análisis. Pero tal vez sea mejor que lo revises por tu cuenta si es que lo necesitas.
Como para cualquier método estadístico ANCOVA asume que ciertos supuestos son cumplidos por los datos. Dependiendo de la pregunta que se quiera resolver con el ANCOVA, algunos de estos supuestos podrían o no ser necesarios de cumplir (entra aquí para una revisión sobre el tema).
Sin embargo, hay un supuesto que sí debe ser cumplido si es que se quiere llegar a determinar diferencias entre grupos. Este es el supuesto de homogeneidad de las pendientes de regresión.
Imaginemos que queremos comparar el alto de cabeza entre machos y hembras de una especie de lagartija (en lagartijas, cabezas más altas generalmente están relacionadas al consumo de presas más grandes y también a un mejor desempeño en peleas con otros individuos). Sabiendo que el alto de la cabeza en estos animales covaría respecto al largo de la cabeza hacemos un ANCOVA. En la siguiente figura vemos las líneas de regresión para machos (puntos negros) y hembras (puntos blancos) que representan la relación entre alto de cabeza y largo de cabeza, y claramente podemos notar que el supuesto de homogeneidad de las pendientes de regresión no se cumple. Basta con ver cómo las líneas de regresión son bastante diferentes en su “inclinación”.
Esto será confirmado si hacemos el ANCOVA ya que la interacción entre covariante (largo de cabeza) y variable independiente (sexo) nos resultará significativa, indicando que las pendientes son significativamente diferentes. Una vez el ANCOVA confirma esto ya no podemos comparar entre sexos utilizando dicho método. ¿Qué se hace en este caso?
Yo me encontré con este problema y para mi sorpresa no me fue fácil encontrar una solución. Estaba algo frustrado ya que, como pueden ver en la figura, es bastante obvio que para un determinado largo de cabeza los machos muestran altos de cabeza mayores a los de las hembras, pero no podía demostrarlo estadísticamente. Mi búsqueda se convirtió en algo casi policial, y de paper en paper me encontré con una técnica bastante oscura pero que solucionaba el preciso problema con el que estaba lidiando. Esta es la técnica de Johnson-Neyman.
Cosas que me sorprendieron del método:
– Lo difícil que fue encontrarlo
– La precisión con la cual abordaba mi problema
– Su edad! El paper original fue publicado en 1936.
La técnica de JN se encarga de resolver casos como el mío, en los que las pendientes de las regresiones de los grupos que quiero comparar son distintas. Este método genera una “zona de no-significancia”, que es básicamente un intervalo en la covariante dentro del cual no hay diferencias entre grupos. Es en las zonas fuera de este intervalo donde los grupos muestran diferencias respecto a la variable dependiente. La siguiente figura explica mejor de qué se trata el método.
No leí el paper original, sino un paper más moderno que explicaba el método de manera más directa (White, 2003). Luego de encontrar el método que necesitaba el siguiente paso era encontrar un software o paquete de R que me permitiera aplicarlo. La rareza del método en la literatura también se reflejaba en su implementación en paquetes estadísticos, solo pude encontrar algunos “bosquejos” de códigos de R e incluso SPSS que no me funcionaban.
Ante esto decidí mirar un poco la base matemática del método. Para mi suerte el paper de White mostraba las ecuaciones en las que el método de JN estaba basado. A pesar de que eran algo tediosas decidí escribir un script de R para poder aplicar el método de manera más directa. Dejaré el script al final por si algún día le sirve a alguien.
Aplicando el método a través de mi script obtuve el siguiente resultado para nuestro ejemplo en lagartijas:
La zona de no-significancia se ubica en un intervalo de largo de cabeza para el cual casi no hay individuos para comparar, de hecho no hay machos adultos en esa zona. La gran mayoría de hembras y machos se ubican fuera de la zona de no-significancia, donde podemos confirmar con tranquilidad que las diferencias entre machos y hembras son significativas. En consecuencia podemos concluir que machos adultos muestran altos de cabeza mayores que las hembras para un largo de cabeza determinado.
Script de R
Para empezar necesitas al menos una base de datos donde las filas sean tus casos y las columnas muestren los valores de tu variable dependiente (en mi ejemplo esta era el alto de cabeza), variable independiente (e.g. sexo) y covariante (e.g. largo de cabeza).
El primer paso entonces es para definir tu tabla de datos, al que llamaremos “data”:
setwd("YourWorkingDirectory")
data <- read.table("YourData.txt",header=T, na.strings = c("x", "NA"))
Suelo tener mis datos en formato .txt pero el script se podría modificar para importar excel (o podrías convertir tu excel a .txt).
El siguiente paso es definir tus dos* grupos:
group1 <- data[ which(data$groups=="0"), ] group2 <- data[ which(data$groups=="1"), ]
En este caso, estoy asumiendo que la columna “groups” codifica ambos grupos como “0” y “1”. Esto puede variar en tus propios datos.
Entonces, definimos nuestros dos grupos como group1 y group2.
*Este script aborda el caso en que quieras comparar dos grupos. Me parece que el método de JN se puede ampliar para considerar más grupos al mismo tiempo, pero no averigüé más acerca de cómo podría hacerse.
En la siguiente línea:
n1 <- 55 n2 <- 33
es necesario cambiar el número de casos que hay en cada grupo. En este caso n1 corresponde al número de casos de group1 y n2 corresponde a group2.
Finalmente:
X1 <- group1$hl X2 <- group2$hl Y1 <- group1$hh Y2 <- group2$hh
tienes que cambiar la última parte de cada una de estas líneas, ya sea “hl” o “hh”. Para mí estas letras significaban “head length” (largo de cabeza) o “head height” (alto de cabeza). Esto debe ser modificado dependiendo de cómo tus variables dependiente y la covariante estén definidas en tu base de datos.
Luego de esto solo queda correr el resto del código:
reg1 <- lm(log(Y1)~log(X1))
reg2 <- lm(log(Y2)~log(X2))
coef1 <- reg1$coefficients
coef2 <- reg2$coefficients
Fcvalue <- qf(.95, df1=1, df2=n1+n2-4)
xmean1 <- mean(log(X1))
xmean2 <- mean(log(X2))
xmeansq1 <- mean((log(X1))^2)
xmeansq2 <- mean((log(X2))^2)
sumx1 <- 0
sumx2 <- 0
sumy1 <- 0
sumy2 <- 0
sumxy1 <- 0
sumxy2 <- 0
xcoord_group1 <- log(X1) # X1
ycoord_group1 <- log(Y1) # Y1
xcoord_group2 <- log(X2) # X2
ycoord_group2 <- log(Y2) # Y2
zx1 <- ((sum(xcoord_group1))^2)/n1
zx2 <- ((sum(xcoord_group2))^2)/n2
zy1 <- ((sum(ycoord_group1))^2)/n1
zy2 <- ((sum(ycoord_group2))^2)/n2
zxy1 <- ((sum(xcoord_group1))*(sum(ycoord_group1)))/n1
zxy2 <- ((sum(xcoord_group2))*(sum(ycoord_group2)))/n2
######## sumx1 ########
c <- 0
while (c<n1) {
sumx1 <- sumx1 + (((xcoord_group1[c+1])^2) - zx1)
c <- c+1
}
sumx1
######## sumx2 ########
c <- 0
while (c<n2) {
sumx2 <- sumx2 + (((xcoord_group2[c+1])^2) - zx2)
c <- c+1
}
sumx2
######## sumy1 ########
c <- 0
while (c<n1) {
sumy1 <- sumy1 + (((ycoord_group1[c+1])^2) - zy1)
c <- c+1
}
sumy1
######## sumy2 ########
c <- 0
while (c<n2) {
sumy2 <- sumy2 + (((ycoord_group2[c+1])^2) - zy2)
c <- c+1
}
sumy2
######## sumxy1 ########
c <- 0
while (c<n1) {
sumxy1 <- sumxy1 + (((xcoord_group1[c+1])*(ycoord_group1[c+1]))-zxy1)
c <- c+1
}
sumxy1
######## sumxy2 ########
c <- 0
while (c<n2) {
sumxy2 <- sumxy2 + (((xcoord_group2[c+1])*(ycoord_group2[c+1]))-zxy2)
c <- c+1
}
sumxy2
########################
########################
########################
######## SSres ########
SSres <- (sumy1-(((sumxy1)^2)/sumx1))+(sumy2-(((sumxy2)^2)/sumx2))
SSres
########################
########################
########################
######## ABC ########
a1 <- coef1[1]
a2 <- coef2[1]
b1 <- coef1[2]
b2 <- coef2[2]
A <- (-Fcvalue/(n1+n2-4))*(SSres)*((1/sumx1)+(1/sumx2))+((b1-b2)^2)
B <- (Fcvalue/(n1+n2-4))*(SSres)*((xmean1/sumx1)+(xmean2/sumx2))+((a1-a2)*(b1-b2))
C <- (-Fcvalue/(n1+n2-4))*(SSres)*(((n1+n2)/(n1*n2))+(xmeansq1/sumx1)+(xmeansq2/sumx2))+((a1-a2)^2)
########################
xlower <- (-B-sqrt((B^2)-A*C))/A
xupper <- (-B+sqrt((B^2)-A*C))/A
xlower
xupper
xlower y xupper indicarán los límites inferior y superior respectivamente de la zona de no significancia.
Plot
Para generar esta figura:
Utilicé este código:
plot(log(data$hl),log(data$hh), ylab="Head height", xlab="Head length") polygon(c(xlower,xlower,xupper,xupper),c(0,3.2,3.2,0), col=rgb(224, 224, 224,maxColorValue=255,alpha=130), border=NA) abline(v=xlower,lty=1, lwd=0.5) abline(v=xupper,lty=1, lwd=0.5) dat <- data[ which(data$group=="1"), ] points(log(dat$hl),log(dat$hh), pch=16 ,col="black") newdata <- data[ which(data$group=="1" ), ] abline(lm(log(newdata$hh) ~ log(newdata$hl))) newdata <- data[ which(data$group=="0" ), ] abline(lm(log(newdata$hh) ~ log(newdata$hl)), lty=2)
Referencias:
– Johnson, P. O., & Neyman, J. (1936). Tests of certain linear hypotheses and their application to some educational problems. Statistical research memoirs.
– White, C. R. (2003). Allometric analysis beyond heterogeneous regression slopes: use of the Johnson-Neyman technique in comparative biology. Physiological and Biochemical Zoology, 76(1), 135-140.




Hi, Ken!
First of all, THANK YOU for this post. It turns out that I am ALSO a PhD which ALSO works with lizards, which ALSO studies the head sexual dimorphism, and which ALSO had to face the same problem with unequality of slopes whan performing an ANCOVA.
For some weeks, I have been looking for a solution to work out this annoying isssue, and I also found the Johnson-Neyman technique. I discovered that there is currently a R package including this test (named “probemod”), but I wasn’t able to fully apply it (given that the creation of a dummy variable for sex was required, and that made its interpretation somehow more difficult… )
Then your post appeared! AND THERE WAS LIGHT!
I will try your script and let you know whether it also worked with my data or not.
Darwin bless you!
P.D.: My mother tongue is spanish too, but I decided to comment in english so as to make it understandable for most readers!
LikeLike
Hi Alicia,
Thank you for writing! It’s nice to hear that the post is potentially helpful for you! I was also struggling with the ANCOVA issue before finding JN. Let me know if you manage to get something out of the script, if not we can try to make it work.
Also, is really nice to find somebody with similar research interests !! I’ll be happy to discuss any lizard-sexual dimorphism-morphology-etc related stuff (of course it can be in Spanish).
Darwin bless you too 😉
LikeLike
Hi again, Ken!
HOORAY! IT WORKED! IT WORKED!
I used your script with snout-vent length as a continuous covariate and head length as a dependent variable, AND I FINALLY GOT RID OF THIS F*&/&%$ING ANCOVA PROBLEM! Results really make sense and will allow me to confidently affirm that the differences between the regression lines of males and females are significative.
Now I am really excited to try all the marvelous and endless posibilities this technique offers to me!
Thank you to infinity and beyond. Darwin bless you again!
P.D.: I followed you on Research Gate. Seems that our research has a lot in common. And of course, you can count on me if your need any help that I could provide you.
LikeLike
Hey Alicia!
Great that it worked!
I’m following you back in research gate so I hope to hear more from you and your research in the future.
All the best!
LikeLike
Pingback: Bigger heads for greener* meals | Ken S. Toyama
Hi Ken,
Why did you use log-format when you calculate the bound?
Michael
LikeLike
Hi Michael,
The reason is that the dataset in the example contains only raw values that have not been log-transformed yet. Every time a log transformation appears in the code is to log-transform a raw column from the dataset.
If your question is more oriented towards why am I using log-transformation at all, it is because in studies of allometry the shape variables (in the example head height) are supposed to escale with size variables (in the example the head length) following a power function. Log transformation is applied so that this relationship becomes linear. This also implies that the data becomes more normalized.
I hope that helps.
– Ken
LikeLike
Dear Ken
Thank you for sharing this guide on the Johnson-Neyman analysis. I am fairly new to R but managed to the analysis with your guidance.
When performing the analysis and wanting to investigate the inferior and superior limits of the non-significance zone, R responds with:
“> xlower
(Intercept)
NA
> xupper
(Intercept)
NA ”
I wonder why this is and would be happy to hear your response.
Kind regards,
Christian
LikeLike
Hi Christian, thanks for writing. It can be hard to know what the problem is with only that information. It would be helpful to see the data and code you are using. Could you put your script here? or, maybe even better, send me an email to ken.toyama@mail.utoronto.ca and we can work on it.
LikeLike
Hello Ken! Thanks so much for sharing this script! I’ll apply it tomorrow and let you know how it goes. Thank you thank you thank you!
LikeLike
Hi Caterina!
I hope it is useful! let me know how it goes and if you come across any issues when trying to make it work.
LikeLike
Hi Ken!
Thanks again for sharing this code – so so helpful! I was wondering if you might be able to help with something.
I get stuck at this point:
c <- 0
while (c<n1) {
sumx1 <- sumx1 + ((((xcoord_group1 [c+1])^2)- zx1))
c <- c+1
}
sumx1
sumx1 = NA
I think this might be because of some missing values in xcoord_group1.
I've tried to apply na.rm = TRUE but in this statement it's not working.
Do you have any further suggestions?
Thanks in any case and have a lovely rest of your day!
Cheers,
Cati x
LikeLike
Hi again Ken! Still Cati 🙂
LikeLike
Hi again Ken!
As I was writing above, I’m getting stuck at
c <- 0
while (c<n1) {
sumx1 <- sumx1 + ((((xcoord_group1 [c+1])^2)- zx1))
c <- c+1
}
sumx1
as sumx1 turns out to be NA.
I thought it was because of missing data in xcoord_group1, but it turns out that might not be the case.
To handle missing data in xcoord_group1, I've added this line at the beginning of the code:
c_xcoord_group1 <- xcoord_group1[!is.na(xcoord_group1)]
c <- 0
while (c<n1) {
sumx1 <- sumx1 + ((((c_xcoord_group1 [c+1])^2)- zx1))
c <- c+1
}
sumx1
Unfortunately sumx1 is still NA…. A tricky one!
If you were able to help that would be super appreciated! Thanks so much in any case and have a lovely rest of your day:)
Cheers,
Cati x
LikeLike
Hi Cati, do you have negative values in your dataset?
LikeLike
Hi Ken, thanks for replying! No I don’t have negative values in the dataset. I have some missing values which I excluded for each operation.
LikeLike
Oh I see… hey if you agree you could send me your dataset and let me know the model you are trying to test. It would be easier to identify the issue that way. If you agree you can just write me at ken.toyama@mail.utoronto.ca 🙂
LikeLike
Pingback: JNplots: an R package to calculate and visualize outputs from the Johnson-Neyman technique – a quick guide | Ken S. Toyama
Hi! Thank you very much for this great post. I am currently fitting my Ancova model with two covariates and for one of the covariates the regression slopes (across all dependent variables) are not equal. How can I apply the JN method with two covariates?
Thanks for the response and best wishes,
Viv
LikeLike
Hi Viv,
When you say that your model has two covariates do you mean that you have two independent variables in total? Something like:
Y ~ X * Z
Or that you have two covariates and one or more predictors (three or more independent variables in total)?:
Y ~ X * Z * W
If your model is like the first one then it should be simple to help you with that. You would just need to choose one of the variables as the ‘predictor’, and the other would act as the covariate (moderator). If this is the case I could suggest something if you give me some more details of your model.
For the second case it is complicated to use the JN technique because of the complexity of the interactions, and I don’t know of any software that has implemented the method for such cases. I think is not impossible though, since some people seem to have addressed the problem mathematically. For a short discussion on this issue, check the last paragraph in Bauer, D. J., & Curran, P. J. (2005). Probing interactions in fixed and multilevel regression: Inferential and graphical techniques. Multivariate behavioral research, 40(3), 373-400.
LikeLike
Hi Ken, Thank you so much for your reply! I have three independent variables (incl 2 covariates) and one predictor variable. Yes, I thought it would be quite complicated to fit such a model as I had trouble finding examples on the internet. Thanks for the literature suggestion. I have now been able to transform my data and am using a different statistical approach – which also makes the interpretation easier.
Nevertheless thanks for your help and time – I really appreciate it.
Best wishes,
Viv
LikeLiked by 1 person